
Django Developers: Be careful with iexact!
May 2025

Background: learning Django and Postgres
This year I taught classes on both Django and Postgres at the same time... and both were new technologies to me. I really enjoyed learning both, and getting to know both of their idiosyncrasies (eg the not-immediately-intuitive structure of PostgreSQL's histograms, which I wrote about here).
As part of my Database class, my students worked through the fantastic online text Use The Index, Luke!. One line on this page stood out to me: "Warning: Sometimes ORM tools use UPPER and LOWER without the developer’s knowledge." I was curious whether this matters in Django, so I asked my students to investigate. The findings were surprising!
Why do indexes matter?
The short answer is that it's way easier to find something specific if the things you're searching are already sorted. Here's a thought exercise to make that clear: imagine that I want to find all the words in english that start with the letters 'data,' and I can choose one of these tools for the task: 1. A dictionary 2. A special dictionary that contains all of the same content as a normal dictionary, but the words are scrambled
It should be obvious that the normal dictionary is better here. We learn at an early age that we can quickly find information in a dictionary (using a process that computer scientists call a binary search). With an unordered dictionary, you would be forced to read the entire thing in order.
Databases all have something similar to ordering, but they can look different. PostgreSQL is pretty opinionated that the data should not be ordered, but provides indexes that behave just like the index at the back of a book - they are their own structure independent of the data, are ordered, and contain information that "points" to the data in the table. There are some trade-offs to using indexes that can get quite complicated, but in general, a query that uses an index as intended will be far faster than a query that searches the entire table, in the same way that a look up in an ordered dictionary is faster than a lookup in a random dictionary.
(side note - I've always wanted to create and print a physical randomly-ordered dictionary that I could use for this point in my classroom.)
Django __iexact
While we were studying indexes in one class, my other class was working on adding search to their Django apps. As a consideration to the user, we wanted to be able to handle inexact searches, e.g. when a user doesn't properly capitalize a name.
We found this helpful tutorial which suggests using Django's __iexact query filter. Note that neither of these references say anything about the performance impact of this filter. As we'll show in a second, that performance impact can be massive.
Setting up an experiment
Each student created a Django ORM model that contains a text string (the example here is a table called Place that contains a column called name), and then used Django migrations to create the matching PostgreSQL table.
The first thing we tried was adding an index on that column using db_index=True in models.py. When we checked the indexes in pgAdmin, we were surprised two find two: the standards index we were expecting, and a second
index that is specifically tuned for LIKE queries. Here are the two definitions (note the varchar_pattern_ops in the second one):
CREATE INDEX IF NOT EXISTS db_place_name_4c1d7804
ON public.db_place USING btree
(name COLLATE pg_catalog."default" ASC NULLS LAST)
TABLESPACE pg_default;
CREATE INDEX IF NOT EXISTS db_place_name_4c1d7804_like
ON public.db_place USING btree
(name COLLATE pg_catalog."default" varchar_pattern_ops ASC NULLS LAST)
TABLESPACE pg_default;
Next, we wanted to make sure that we understood how Django ORM code gets converted into SQL queries. We turned on Django's query logs, wrote some ORM code, looked at the queries that it produced, and then ran them in pgAdmin.
We wrote two queries - one that intentionally uses the index we just created, and another that is identical, except that it includes __iexact and (as expected) does not use the index.
Here are the two queries:
Place.objects.filter(name="Leonard LLC").count()
Place.objects.filter(name__iexact="Leonard LLC").count()
And the queries they generate and their queryplans
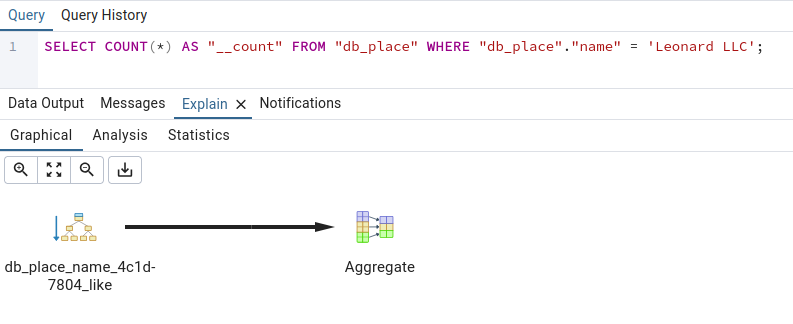
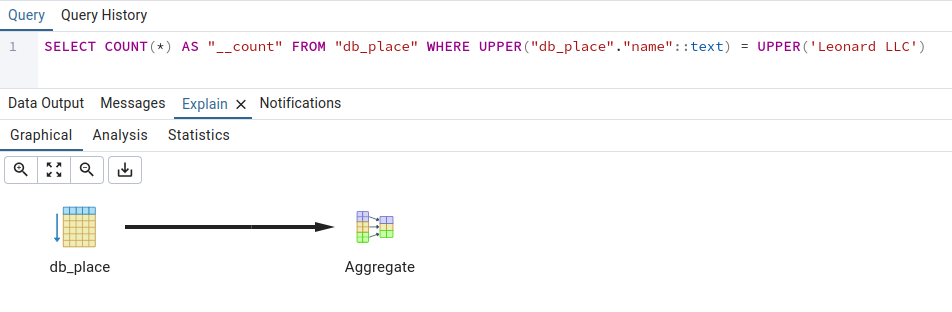
(the .count() is a little bit of a hack - it gets around Django's delayed QuerySet execution)
Quantifying The Difference
We knew that adding __iexact() to our ORM code prevented the use of the index. Next, we wanted to understand the impact. Did not using the index actually matter? To quantify, we designed an experiment.
We used time.perf_counter() to time how long a single query takes. We wrote a loop that alternates running the normal query and the __iexact() query a bunch of times each, logs their runtimes, and then reports the average runtime for each.
Finally, we repeated this process a few times with different table sizes - up to a million records. We used Faker and Django's bulk_create() to make adjusting the table size easy.
If you want to replicate this experiment, my code is here: https://github.com/MrJonesAPS/orm/blob/main/03_ORM_Limitations.py
Results - indexes matter, especially with big tables
For small tables, the difference was minimal. Even with a few thousand records, the two versions of the queries often gave almost exactly the same runtime. As the tables grew, the difference became far more obvious - the query that used the index remained fast while the query that had to perform a full table scan got quite slow - more than four seconds for a table with one million records.
Here the a nice graph that one of my students made (shared with permission - thanks Adam!)
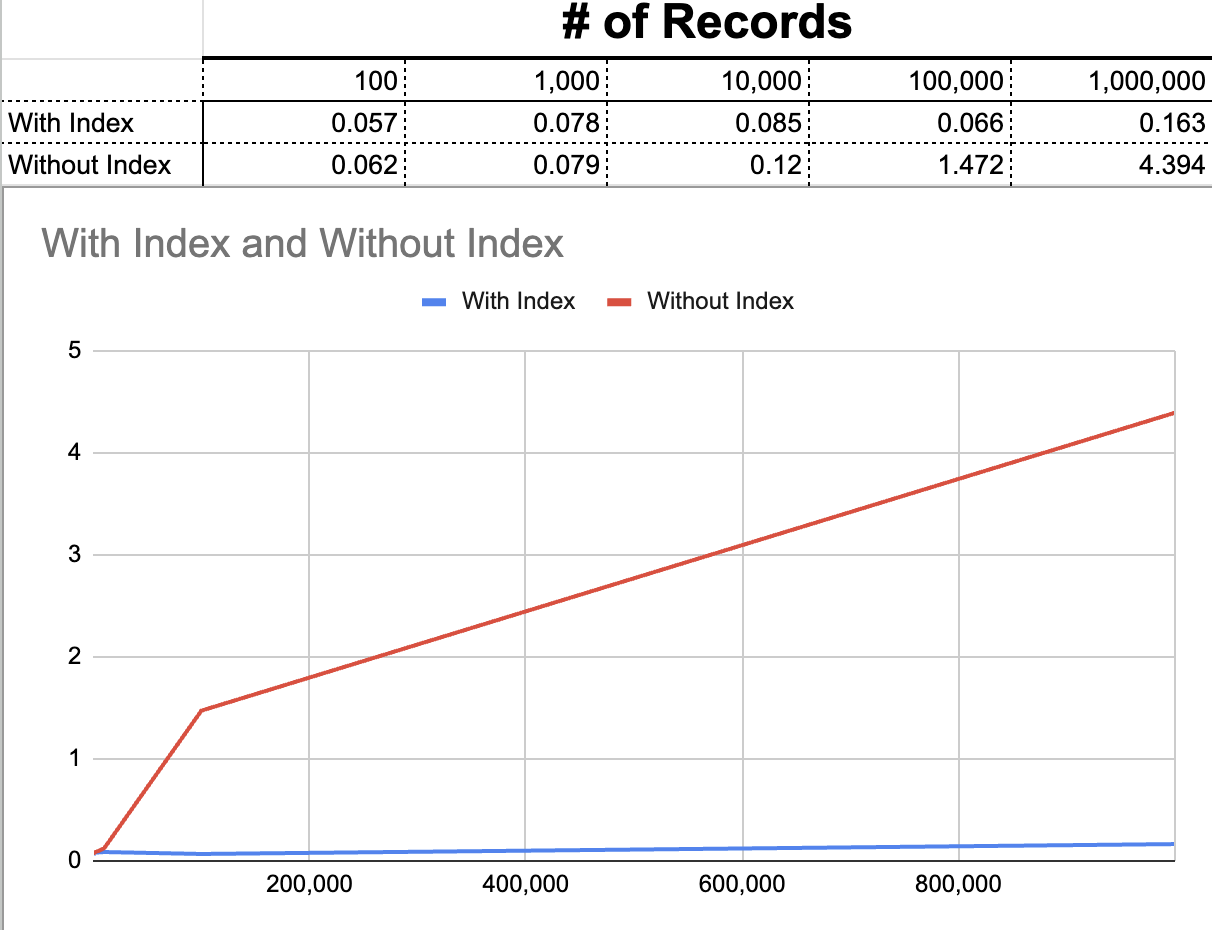
Finally, we discussed the impact that this would have on a large Django project - if lots of users are using your app at the same time, this difference could be catastrophic!
Reflection
Experimentation in CS Classrooms
I'm always looking for ways to emphasize the science in computer science. In CS, we usually focus on "how can I get this to work" (I love Elmo's catch phrase "I wonder, what if, let's try!"), and less on designing experiments to help us understand how things work.
In my mind, the term science makes me think of physics classrooms where students discover rules through experimentation (I recently helped a student with a physics homework assignment where they had to make a bunch of pendulums with different lengths and time them). So I was especially excited about the experiment that we setup to test the difference between the two queries.
While we were creating this experiment, we had discussions about how it's important to control variables. We identified that server load is an important variable, so we chose to alternate between trials of the fast and slow query.
I'm looking for other ways to incorporate the scientific method and experimental design into my CS classes, and I'd love to hear from others who have done the same.
A gentle introduction to algorithmic complexity
None of these students have taken an algorithms class yet, so they didn't reason in terms of Big O notation - most will learn about that next school year.
I will be excited to check in with them when they do - I hope that this experience
will give them an intuitive foundation when they learn about the difference between
algorithms whose complexity scales as a function of their input (O(n)) vs the log of their input (O(log n)).
Extension - Efficient case-insensitive searches?
The conclusion of this experiment was that case-insensitive searches are costly. We did not continue on to determine a better solution.
Use the Index, Luke suggests two solutions: a persisted computed column, or a function-based index. Both sound like they would work, but each has overhead - especially if you want to search large tables or multiple text columns.
Databases have a concept called Collation which can be manipulated to determine how data is sorted and compared. I'd be interested to explore more about whether there is a way to create a case-insensitive collation in PostgreSQL, or a strategy like varchar_pattern_ops, which Django automatically adds for LIKE queries.